International Conference for Free and Open Source Software for Geospatial
August 14-19, 2017
Seaport Hotel & World Trade Center
Boston, MA
Presented By OSGeo
International Conference for Free and Open Source Software for Geospatial
August 14-19, 2017
Seaport Hotel & World Trade Center
Boston, MA
Presented By OSGeo
We geocode data, projecting place names into some coordinate system. Sometimes these places, which have a significant spatial extent, are unfortunately geocoded to a single point. When this happens, the zip codes of Boston are associated with a point in the center of the city and the zip codes of Massachusetts are associated with a point in the center of the state. This approach really hinders spatial search. For spatial search, we really need a bounding box that encloses feature. Spatial search in OGP requires the user to map and zoom the map to their area of interest. If they are interested in Massachusetts statewide data, they zoom out to see the entire state. Search is fundamentally about ranking, trying to get the most appropriate items at the top of the search results. Spatial search intersects the extent of the map with the extent of each layer to compute this ranking. In our example where bounding boxes are available, it is easy to image how the ranking of city level and state level data changes as the user pans and zooms. However, if we geocode to center points our spatial search algorithms fail. Since we don’t how much of any layer intersects the map, we can’t rank small layers higher when the user zooms in and lower when they zoom out. If you hope to do spatial search on your data, I think you have to find a way to geocode to a bounding box.
If you have a good way to geocode to a bounding box, let me know! If you’re dealing with US data, there’s a data set of state and county bounds from the Newberry Library. It even has historical boundries over time. This beautiful data set available as a shapefile or KML (17727 different boundaries, various resolutions). It covers states and counties, but lots of things aren’t either. For example, Boston isn’t (it’s in Suffolk County with several other towns). So Boston isn’t in the Newberry Library data set. Neither is your local airport or river. If you have another way to convert place names to counties, a two step process might work.
Geonames has a lot of stuff. Their free data set geocodes a name to a point and provides the name of the county it’s in. If your locations are in the US, Newberry Library could provide a bounding box for the county.
Geonames sells a premium data service. For 720 euros a year you get the extent of about 100,000 administrative divisions as bounding boxes. I haven’t used this data, but a free sample is available.
The use of bounding boxes is also critical for heatmaps. If you have an extent for every layer, your heatmaps will look great. Imagine a map overlay with your state covered in a background haze with cities being sizable bright regions. That’s trivial if you have bounding boxes. In your data is geocoded to points, you’ll get something pretty ugly: a small bright spot in the center of your state and tiny bright dots over each city. Heatmaps, like spatial search, really need bounding boxes.
I think there’s a need for reconfigurable spatial search components that streamline the creation of spatial portals. These components need to be created on a flexible framework supporting “reconfigurableness”. Jonathan Gale introduced me to Banana. It integrates with Solr and is a port of Kibana (which works with Elastic Search). The user builds their UI in the browser by instantiating and configuring individual components. Need table of search results? Just drop it in and select which Solf fields you want displayed. Need a text input box for search terms? Drag and drop it where you want it. Once the UI is complete, it can be saved, frozen and deployed.
Here’s the current results of my crude explorations:
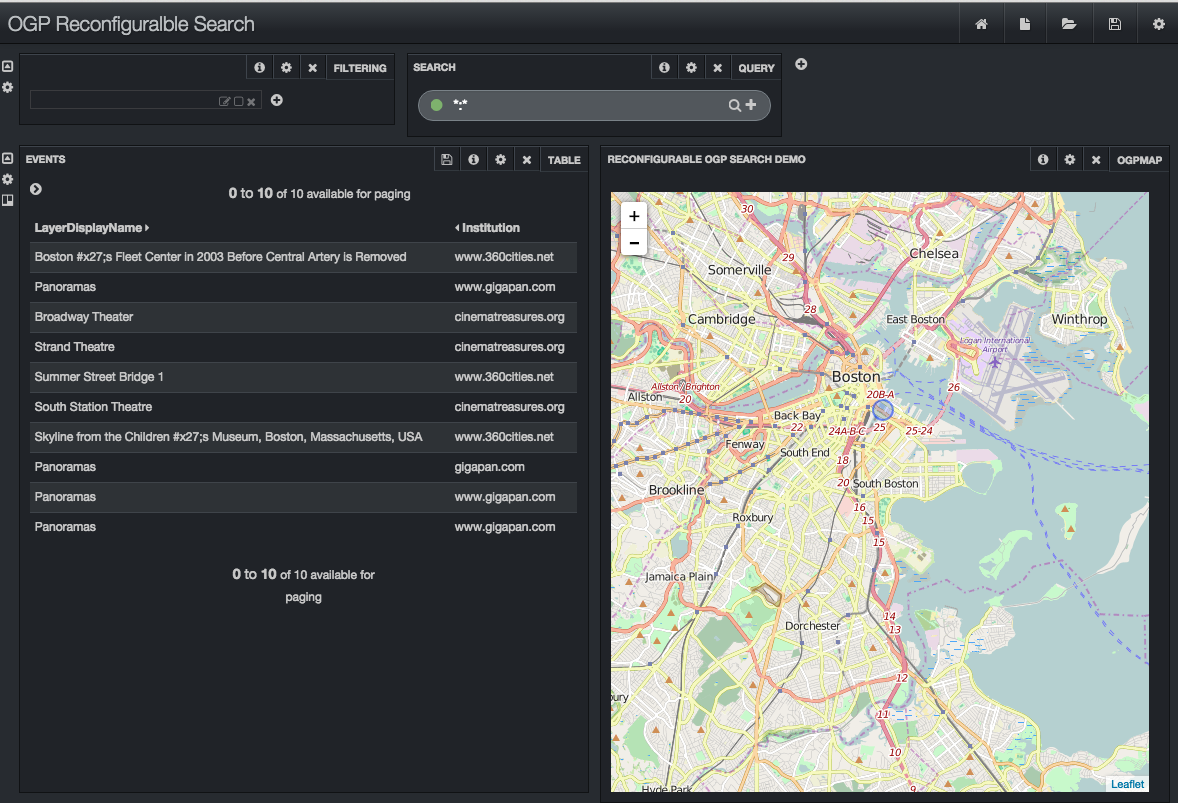
The map uses Leaflet. Search results are from an OGP Solr schema populated with data from a web crawl . As with OGP, the search results update as the map changes. As with OGP, as you mouse over the search results the layer’s location is indicated on the map (notice the small blue circle near the center of the map). There’s no preview or download.
If you have other suggestions for reconfigurable UI frameworks, please let me know. I’d be happy to consider other options. But, I do think a framework approach significant advantages. First, I don’t have to invent and code configuration. Instead, it is provided by the framework. For example, here’s a config tab for the table that displays the table of search results:

As configured, just two of the Solr fields (LayerDisplayName and Institution) are displayed (in 9 point font) in the search results. Adding another field just requires a couple mouse clicks or editing the right config file. If you don’t want a header, just click the check box to turn it off. If you don’t know what the “Trim Factor” option is, just mouse over the question mark icon. Creating a search application that is independent of the Solr schema can be a challenge. By using a framework like Banana the schema details are a configuration issue. Any schema can be accommodated via these configuration tabs on the reusable components. Maybe you would like to swap the map and the search results so the map on the left side and the search results on the right? In Banana, that reconfiguration takes exactly three mouse clicks.
Banana is based on Angular 1.2. Angular 2, now in beta, is incredibly different from Angular 1.2. If it is successful, we’ll end up with a reconfigurable Solr framework that is very different from the existing Banana. Also, Banana faces some competition from Lucid’s non-open source components in SILK. Still, I think Banana is a reasonable choice for creating reconfigurable spatial search components. I’m very interested your thoughts at SpacemanSteve@gmail.com.
A single page web app like OpenGeoPortal contains thousands of lines of application code and many large JavaScript libraries. Testing on all the popular browsers is difficult. It requires VMs or multiple machines to run specific browsers (e.g., IE and Safari). Running specific, old versions of browsers is a problem as they automatically and frequently update themselves. Since I run on OS X, I can’t locally run Microsoft’s Edge or various versions of IE so compatibility testing used to be difficult. With BrowserStack, you can run any browser within your browser. It starts a VM running whatever operating system and browser. They connect with your browser via a plugin. In only 20 seconds I started a VM with Windows 10 and Edge for OGP compatibility testing. BrowserStack is useful when you need specific versions to test with: Firefox version 35 on OS X, Chrome on Windows 8.1, etc. It isn’t free but they do provide free accounts to developers on open source projects and students.
I render Solr heatmap data over base maps. So far, I haven’t made nice looking heatmap map layers without using a classification algorithm. Typically, the desired heatmap (perhaps based on Brewer colors) has 7 colors. So the document counts from Solr are through Jenks to create 7 categories. A color gradient is created with color stops where the Jenks based categories align with the colors from the color map. As discussed in a previous post, performance is important.
Jack Reed asked me a great question: is classification based on ckmeans a better option than Jenks? I hadn’t heard of ckmeans, but there’s a really nice JavaScript library that implements it. A brief investigation suggests it isn’t an improvement over Jenks. ckmeans from simple_statistics.js produces nearly the same classifications as Jenks from geostats.js. Based on Chrome’s timing feature, Jenks runs slightly faster.
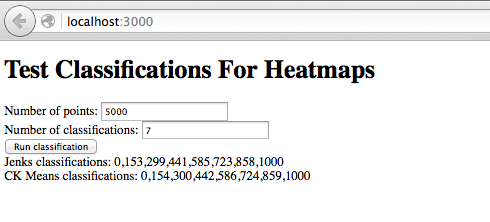
I ran ckmeans and Jenks in two different ways. The first used collections of random numbers generated in a small Angular 2 based site. The site allowed the user to enter the desired number of points and the desired number of classifications. Math.random created integers between 0 and 1000. Using this TypeScript code and 5000 points, Jenks classifications required 1.45 seconds while ckmeans required 1.9 seconds. The classifications generated by the two algorithms were nearly identical:
Jenks classifications: 0,149,299,435,572,708,853,999
CK Means classifications: 0,151,301,441,574,713,856
While this test was useful, one could argue classifying randomly generated numbers wasn’t a good test case. Ideally, heatmap numbers from a Solr response should be used. So, I tried that too. Again, Jenks ran more quickly. For roughly 10000 points, the time was 3.9 seconds for Jenks versus 6.3 for ckmeans. For roughly 5000 points, 1.06 versus 1.74. Again, the classifications were very similar:
jenks [0, 39, 161, 361, 686, 1000, 1266, 1801]
ckmeans [0, 33, 152, 354, 574, 812, 1136, 1453]
I don’t claim my testing was exhaustive. I tried two different ways and they agreed. Then, I returned to billable work. If you have other suggestions or ideas, just let me know. I’m happy to explore ideas to make the heatmaps work better and faster.
I’ll close with some less useful details. I liked the tutorials on the Angular 2 site. Nic Raboy had a great post on calling Javascript libraries from TypeScript. Here’s a screenshot of my Angular 2 app:
 And here’s the Angular 2/TypeScript code that responds to the button click:
And here’s the Angular 2/TypeScript code that responds to the button click:
// the event handler for the “compute” button
onSelect() {
let data = AppComponent.makeArray(this.numberOfPoints);
let g = new geostats(data);
let jenksClassifications = g.getClassJenks(this.numberOfClassifications);
// jenks returns lower bounds of each classification
this.jenks = jenksClassifications.toString();
let ckmeansClassifications = ss.ckmeans(data, this.numberOfClassifications);
// ckmeans returns all data in sorted arrays of arrays
// get lower bounds of each classification by take first element of array
let ssClassifications = [];
for (var index = 0 ; index < ckmeansClassifications.length ; index++)
ssClassifications.push(ckmeansClassifications[index][0]);
this.ckmeans = ssClassifications.toString();
}
// utility function to return an array of random numbers
static makeArray(size)
{
let a = [];
for (var i = 0 ; i < size ; i++)
a.push(Math.round(Math.random() * 1000));
return a;
}
I really enjoyed playing around with Angular 2 and hope to do more in the future.
We can create a nice summary of the search results by displaying Solr generated heatmap data on the map. Solr implements heatmaps like a facet. To obtain an array of counts the Solr query must include heatmap.facet=true, the map extent, and some other details. Using a pyramid of grid levels that were set during document ingest, Solr returns an array of document counts for an area larger slightly larger than the map. These documents counts must be turned into heatmap colors. The colors are assigned using the Jenks classification algorithm. If the heatmap color scheme as n colors, we request n classifications from Jenks. Once the classification has been computed, the heatmap layer can be drawn. As the map zooms in and out, Solr selects the appropriate level in its pyramid of grid levels. Which level is selected determines the number of cells in the heatmap, the default level can be overridden via query parameters. You can see some Solr based heatmaps at http://WorldWideGeoWeb.com.
I investigated the performance of client side heatmap rendering code because a high resolution heatmap updated slowly. My analysis used Google Chrome’s Developer Tools. Using OpenLayers 2, rendering the heatmap layer takes under 250ms, often closer to half that time is needed. It varies a little with the number of cells, but not much. It turns out most of the time is spent computing the Jenks classifications.
For example, when the counts array is 81×49 and contains 743 non-zero values, computing the Jenks classifications takes 700ms. When the count array is 161×97 with 2033 non-zero values, Jenks classifications takes roughly 9 seconds. Once those classifications are computed, rendering the time to render the data in OpenLayers increases very slightly.
I do not know the computational complexity of the Jenks algorithm. According to wikipedia, many other classification algorithms are NP-Hard, perhaps Jenks is as well. (For NP-Hard problems, as the size of input grows the time to compute the answer grows very quickly.) To reduce the time required for Jenks classifications I explored running the classification algorithm on only a subset of the counts data returned by Solr. That is, we request a high resolution heamap from Solr but compute the Jenks classification using only a subset of the heatmap data. I believe these explorations were successful. The first images below shows Jenks classification based on all the data followed by an image with classification based on the half of the data (those with an even index).


To show a significant non-trivial difference, here’s an image where the classification algorithm only used every tenth point:

Generating the heatmap classification based on just a sampling of Solr’s returned document counts seems to work well. It has a small impact on the heatmap’s appearance but greatly improves performance.
While using a sample has a small impact on the image, it does affect the boundaries the Jenks algorithm computes. The following table show the boundaries computed using all the data, the data at even indexes and the data data at odd indexes:
all data: [0, 33, 138, 324, 516, 758, 1000, 1266, 1801]
even indexes: [0, 37, 148, 324, 509, 858, 1165, 1509, 1801]
odd indexed: [0, 22, 97, 310, 516, 686, 928, 1266, 1801]
If you’re interested in reading more about Jenks, check out Tom MacWright’s interesting post.
When OGP search was implemented there were no spatial features in Solr. How do the new spatial features impact OGP? Currently, OGP stores the layer’s bounding box as four separate numeric fields (named MinX, MaxX, MinY and MaxY). It also stores the geodetic coordinates as CenterX and CenterY, Area (in degrees squared), and the HalfWidth and HalfHeight (used to test for intersections).
Solr spatial provides several field types specifically for spatial information. The RPT field (Recursive Prefix Tree) is especially noteworthy because it supports heatmaps. Fields of type RPT are populated with WKT (Well Known Text) values. For a bounding box, this is an envelope. There is a BBoxField type which, unsurprisingly, holds an axis aligned bounding box. Finally, RptWithGeometrySpatialField is an RPT field that also stores the original coordinates and uses them for more accurate intersection testing. (I believe the RPT intersection is based exclusively on grid cells. With RPT, two polygons that do not actually intersect but are both contained within a lowest level grid cell would incorrectly be reported as intersecting. For fields of type RptWithGeometrySpatialField, Solr does a more detailed check also using the polygon vertices.)
OGP includes a bounding box based filter query that excludes layers that do not intersect the map. It uses several values (the layer’s center x and y, half width and half height) to determine which layers intersect the map. This can be done more easily using either an RPT or BBoxField and a geofilt filter. It would be more efficient than the existing filter query.
OGP scoring compares the region covered by the map to the bounding box of each layer. It does this by creating a grid of 9 points on the map and counting how many of these points are in each layer. Solr spatial has a better solution, it can score layers based on their percentage overlap between the map and each layer’s bounding box. This can only be used with fields of type BBoxField (not with RPT fields). OGP also has a scoring component that compares the area of the map (in square degrees) to each layer. With spatial Solr’s percentage overlap rank function we probably don’t need the separate area based component. New queries built with Solr spatial would be more efficient than the current queries.
There is an existing Solr query component that uses the center of the map and scores layers based on their center. The existing version uses the float fields Center_X and Center_Y. This should be changed to a Center field of type LatLonType. Distance based queries (e.g., find layers within 5 miles of 42, -71) would be easy to implement with the LatLonType.
Solr can generate heatmaps based on spatial fields. Simply use an RPT field and request a heatmap facet on that field. The query also contains an bounding box that defines the area of interest. Solr returns an grid of counts that covers a slightly larger region (that aligns with its grid cells). These counts can be turned into various colors. For an example, see my site at http://www.WorldWideGeoWeb.com.
By incorporating spatial Solr features OGP could be both more efficient and more flexible. Queries would be much easier to understand, adding to maintainability. This requires adding new fields of type BBoxField, LatLonType and RptWithGeometrySpatialField (Center, BBox, BBox_RPT) and deleting several old fields (Center_X, Center_Y, HalfWidth, HalfHeight, MinX, MaxX, MinY, MaxY).
I’ll be blogging on search and Solr related issues. This first post reviews how search is currently implemented. Future posts will discuss new spatial features in Solr such as the spatial data types, advanced spatial query functions and heatmaps.
Searching a set of documents consists of two separate operations: filtering and ranking. First, we apply filters that exclude documents that are not relevant. Second, a score for each relevant document is computed which indicates how well the document matches the query. These results are ordered by this score. With Solr you generate a single query that incorporates both filters and scoring information.
In OGP, the simplest searches come from just moving the map. Every zoom or pan event by the user defines a new map extent and so requires a new query incorporating both filtering and ranking. Since it was written several years ago, OGP uses old Solr features (mostly 1.4) rather than the newer spatial features. The query first filters out all layers that do not intersect the map extent. This leaves potentially thousands of layers that do intersect the map. They need to be ranked so the most appropriate layer can be presented to the user. Several separate factors are computed and combined to compute the spatial score. The query ranks each relevant layer’s center and area based on how it compares to the map’s area area and center. It also generates a grid of nine points on the map and ranks each layer based on how many of these points it contains. Finally, it gives layers completely contained within the map a small ranking boost. Essentially, the query is ranking the bounding box of each layer based on how similar it is to the bounding box of the map.
Spatial properties drive OGP search but there are other components. Entering one or more terms in the basic search box results in a typical Solr text search against fields such as layer name, ISO, theme and place keywords, publisher, originator and institution. Layers that do not match the text search terms are filtered out. Layers that do match get a score based on the quality of the match. For each layer, this text-based score combines with the spatial scores yielding a total score. The results are ranked by total score and presented to the user.
Combining the spatial and textual scores for each layer is basically a weighting problem. How important, for instance, is the score based on the layer’s center as compared to the score based on the layer’s area. Alternatively, how important is matching a search term in the layer title field versus matching the term in the publisher field. In OGP the weights in decreasing order of importance are area match, number of grid points in layer, center match. Spatial terms are weighted more heavily than text based terms. A text search against a layer title is worth twice as much as a match in the other keyword fields.
Using Advanced Search one can have additional filters applied to the document set. For example, one can filter based on the type of data (raster, vector, etc.), the institution publishing the data, a date range, etc. These filters remove documents from the list of relevant documents.
In OGP, the Solr query is constructed on the client. The code resides in the file solr.js. A jsonp query is sent directly to the Solr instance. No server-side intermediary is used. Nor are there any Solr plugins. Instead a long, complex query is sent for every search request. It is important to protect the Solr server with a firewall. This firewall should allow select requests from any IP address but limit update URLs to your admin machine’s IP addresses.
Through the Open Geoportal Stanford, Tufts, Columbia, UC Berkeley, and Harvard are working together to document, archive, and serve up all of the National Atlas data that went offline last fall. The project is near completion and all the data and metadata will be available around February 2015.