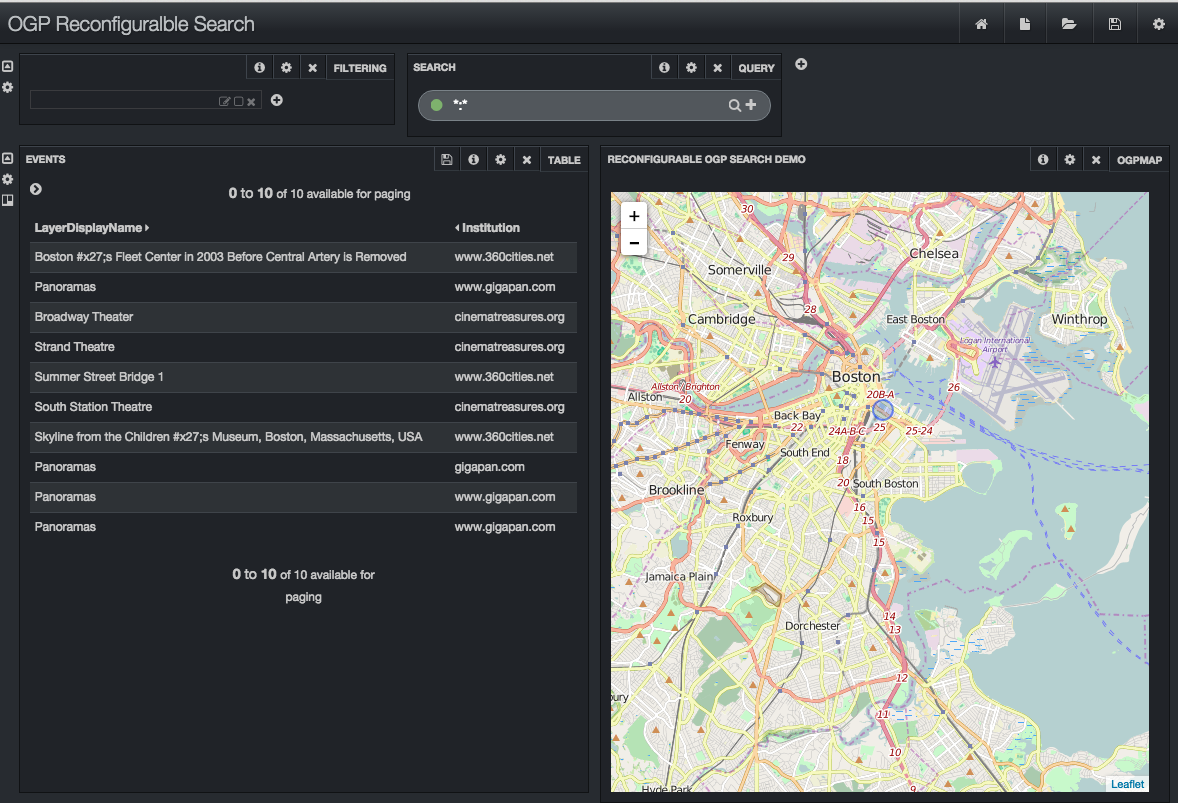
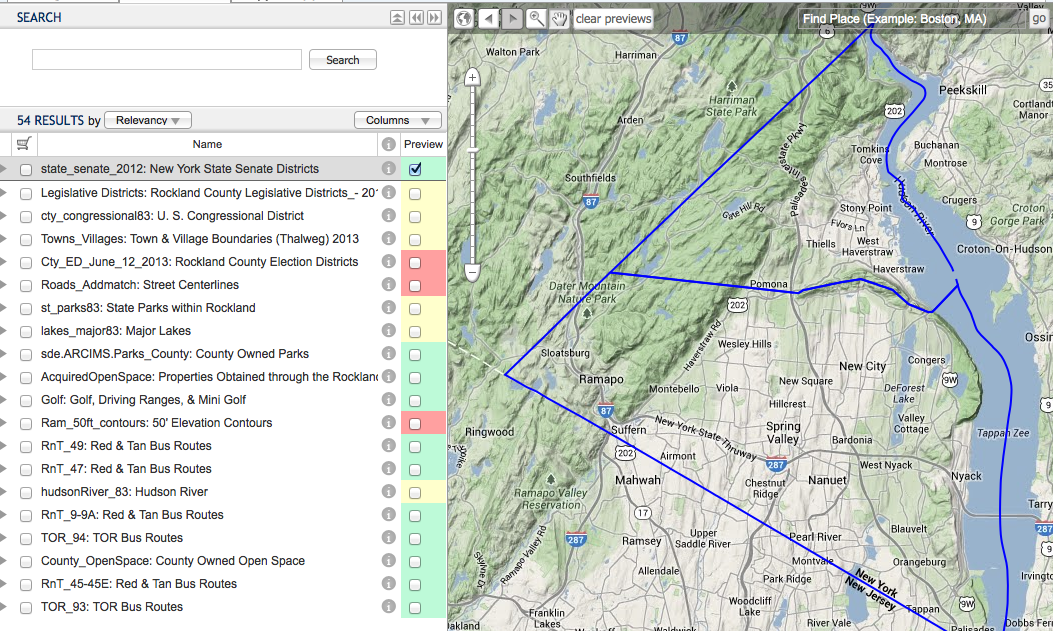
We geocode data, projecting place names into some coordinate system. Sometimes these places, which have a significant spatial extent, are unfortunately geocoded to a single point. When this happens, the zip codes of Boston are associated with a point in the center of the city and the zip codes of Massachusetts are associated with a point in the center of the state. This approach really hinders spatial search. For spatial search, we really need a bounding box that encloses feature. Spatial search in OGP requires the user to map and zoom the map to their area of interest. If they are interested in Massachusetts statewide data, they zoom out to see the entire state. Search is fundamentally about ranking, trying to get the most appropriate items at the top of the search results. Spatial search intersects the extent of the map with the extent of each layer to compute this ranking. In our example where bounding boxes are available, it is easy to image how the ranking of city level and state level data changes as the user pans and zooms. However, if we geocode to center points our spatial search algorithms fail. Since we don’t how much of any layer intersects the map, we can’t rank small layers higher when the user zooms in and lower when they zoom out. If you hope to do spatial search on your data, I think you have to find a way to geocode to a bounding box.
If you have a good way to geocode to a bounding box, let me know! If you’re dealing with US data, there’s a data set of state and county bounds from the Newberry Library. It even has historical boundries over time. This beautiful data set available as a shapefile or KML (17727 different boundaries, various resolutions). It covers states and counties, but lots of things aren’t either. For example, Boston isn’t (it’s in Suffolk County with several other towns). So Boston isn’t in the Newberry Library data set. Neither is your local airport or river. If you have another way to convert place names to counties, a two step process might work.
Geonames has a lot of stuff. Their free data set geocodes a name to a point and provides the name of the county it’s in. If your locations are in the US, Newberry Library could provide a bounding box for the county.
Geonames sells a premium data service. For 720 euros a year you get the extent of about 100,000 administrative divisions as bounding boxes. I haven’t used this data, but a free sample is available.
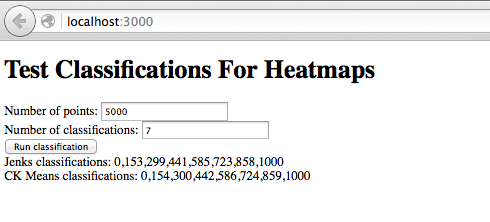
The use of bounding boxes is also critical for heatmaps. If you have an extent for every layer, your heatmaps will look great. Imagine a map overlay with your state covered in a background haze with cities being sizable bright regions. That’s trivial if you have bounding boxes. In your data is geocoded to points, you’ll get something pretty ugly: a small bright spot in the center of your state and tiny bright dots over each city. Heatmaps, like spatial search, really need bounding boxes.